You are looking at documentation for an older release.
Not what you want? See the
current release documentation.
ICU Normalization Token Filteredit
Normalizes characters as explained
here. It registers
itself as the icu_normalizer token filter, which is available to all indices
without any further configuration. The type of normalization can be specified
with the name parameter, which accepts nfc, nfkc, and nfkc_cf
(default).
You should probably prefer the Normalization character filter.
Here are two examples, the default usage and a customised token filter:
PUT icu_sample
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"nfkc_cf_normalized": { 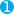 "tokenizer": "icu_tokenizer",
"filter": [
"icu_normalizer"
]
},
"nfc_normalized": {
"tokenizer": "icu_tokenizer",
"filter": [
"icu_normalizer"
]
},
"nfc_normalized": {  "tokenizer": "icu_tokenizer",
"filter": [
"nfc_normalizer"
]
}
},
"filter": {
"nfc_normalizer": {
"type": "icu_normalizer",
"name": "nfc"
}
}
}
}
}
}
"tokenizer": "icu_tokenizer",
"filter": [
"nfc_normalizer"
]
}
},
"filter": {
"nfc_normalizer": {
"type": "icu_normalizer",
"name": "nfc"
}
}
}
}
}
}
|
Uses the default |
|
Uses the customized |