similarityedit
Elasticsearch allows you to configure a scoring algorithm or similarity per
field. The similarity setting provides a simple way of choosing a similarity
algorithm other than the default TF/IDF, such as BM25.
Similarities are mostly useful for string fields, especially
analyzed string fields, but can also apply to other field types.
Custom similarites can be configured by tuning the parameters of the built-in similarities. For more details about this expert options, see the similarity module.
The only similarities which can be used out of the box, without any further configuration are:
-
default - The Default TF/IDF algorithm used by Elasticsearch and Lucene. See Lucene’s Practical Scoring Function for more information.
-
BM25 - The Okapi BM25 algorithm. See Plugggable Similarity Algorithms for more information.
The similarity can be set on the field level when a field is first created,
as follows:
PUT my_index
{
"mappings": {
"my_type": {
"properties": {
"default_field": { 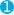 "type": "string"
},
"bm25_field": {
"type": "string",
"similarity": "BM25"
"type": "string"
},
"bm25_field": {
"type": "string",
"similarity": "BM25"  }
}
}
}
}
}
}
}
}
}
|
The |
|
The |